

Sentinel: SOTA Model to Protect Against Prompt Injections
Introduction
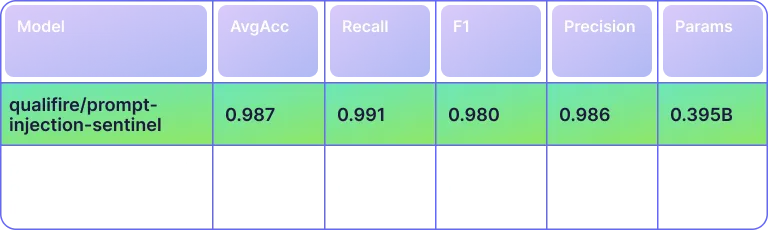
Prompt injection remains one of the most stubborn attack vectors against Large Language Models (LLM’s) and LLM powered agents. Sentinel - released as open weights model, qualifire/prompt-injection-sentinel, is a novel detection model based on the answerdotai/ModernBERT-large architecture with a rigorously curated and synthesized, diverse training set. On a comprehensive internal test set, Sentinel attains 0.980 F1-score, outperforming previous strong baselines by wide margins while maintaining ~20ms inference latency on a single NVIDIA L4 GPU.
Why Prompt Injection Persists
Prompt injection attacks, malicious prompts that hijack a large language model’s intended behaviour, range from simple directives like”ignore previous instructions” to sophisticated, jailbreak-style exploits using role playing, obfuscation, character escaping, or context withholding. They constantly evolve, using template-driven patterns, generative techniques, and automated optimization to keep producing new variants.
Effective LLM security hinges on prompt-injection detection: binary classifiers fine tuned on balanced datasets of benign and hostile inputs (such as protectai/deberta-v3-base-prompt-injection), further hardened through adversarial training and smart input preprocessing. Techniques such as LLM-as-a-judge are unsuitable in this context, because the “judge” model is just as vulnerable to prompt-injection as the system it is meant to evaluate.
As adversarial tactics keep evolving, sustaining jailbreak resilience and safety across LLM vendors demands two pillars: vendor agnostic, dynamic benchmarks that track new attack patterns and diverse, continuously refreshed training sets that inoculate models against them.
The Sentinel Detection Model
Model Architecture - leveraging ModenBERT
Sentinel is built on the backbone of answerdotai/ModernBERT-large. Rotary positional embeddings (RoPE) maintain long-range fidelity, while Local-Global Attention and Flash Attention keep inference fast and memory-efficient. That lets Sentinel scan full, multi-page prompts for injection signals without truncation—perfect for real-time LLM security workflows.
Results
Due to its 395M parameters, Sentinel’s architectural optimizations yield ~20 ms latency on modest L4 hardware, enabling inline evaluation for interactive LLM applications without noticeable overhead.
In the chart below you can see that Sentinel posts 0.987 average accuracy—13.9 pp above the baseline—and an F1 of 0.980 versus 0.728, these results attributed to both ModernBERT architecture and the extensive and diverse training dataset.
Performance on the Internal Held-Out Test Set
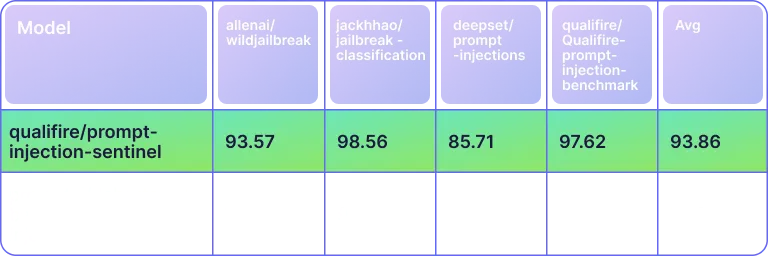
Across four rigorous public prompt-injection benchmarks, Sentinel outshines the DeBERTa-v3 detector on every dataset, posting an average F1 of 0.938—nearly 23 points ahead of the baseline’s 0.709—clear proof of its superior robustness and generalization.
Benchmark Performance (Binary F1 Score)
Conclusion
Sentinel combines the power of ModernBERT with a rigorously curated, ever-evolving dataset to deliver real-time prompt injection protection at sub-20 ms latency on cost-effective hardware, ensuring your AI systems behave exactly as you intended. By continuously updating its benchmarks and remaining vendor-agnostic, Sentinel adapts to emerging jailbreak techniques without sacrificing performance or adding complexity to your deployment. Ready to secure your LLMs with state-of-the-art evaluations, safeguards, and controls.
Sentinel: SOTA Model to Protect Against Prompt Injections




.png)