

AI Evaluator Arena: Blind comparisons for AI judges
Intro — TL;DR
EvalArena by Qualifire is a Hugging Face Space that runs blind comparisons of AI evaluators. Pick a test type, load an example, compare two blind judge outputs, vote for the better evaluation, then watch the ELO leaderboard update. Try it on Hugging Face: https://huggingface.co/spaces/qualifire/EvalArena
Why EvalArena Matters
When using an LLM to act as a judge you often operate blindly, lacking data about the actual performance and detection rate of the model you trust to supervise your critical AI workflows. We created the eval arena to pit all the top of the line LLMs against each other in real world use cases so that you can make informed decisions about choosing the right tool for the job.
What EvalArena does
- Runs blind, pairwise comparisons: two judge outputs, identities hidden until you vote.
- Offers four test types: Grounding, Prompt Injections, Safety, and Policy checks.
- Lets you load an example or pick a random sample from the datasets powering the tests.
- Updates a public ELO leaderboard after each vote, creating an aggregated preference signal teams can act on.
These test datasets and models live in the Qualifire Hugging Face ecosystem, for example the grounding and prompt-injection benchmark datasets used to seed the Space.
How it works:
- Choose a test type from the dropdown, for example grounding or prompt injection.
- Load an input example or use a random dataset item.
- Click Evaluate, review two blind judge outputs, pick the better assessment.
- See which judge produced each assessment, observe ELO changes on the leaderboard.
This human-in-the-loop preference is a low-friction way to produce reliable, labeled comparisons that correlate with real developer judgments.
The Judges:
- Qualifire
- Meta Llama 3.1 70B Instruct
- Meta Llama 3.1 405B Instruct
- Meta Llama 4 Scout 17B 16E Instruct
- Meta Llama 4 Scout 32K Instruct
- Meta Llama 3.1 8B Instruct
- Gemma 3 27B
- Gemma 3 12B
- Mistral (7B) Instruct v0.3
- o4-mini
- GPT-4.1
- GPT-4o
- GPT-3.5 Turbo
- GPT-5
- Claude 3.7 Sonnet
- Claude 4 Sonnet
- Qwen 2.5 72B Instruct
- Qwen 2.5 7B Instruct
- DeepSeek V3
- DeepSeek R1
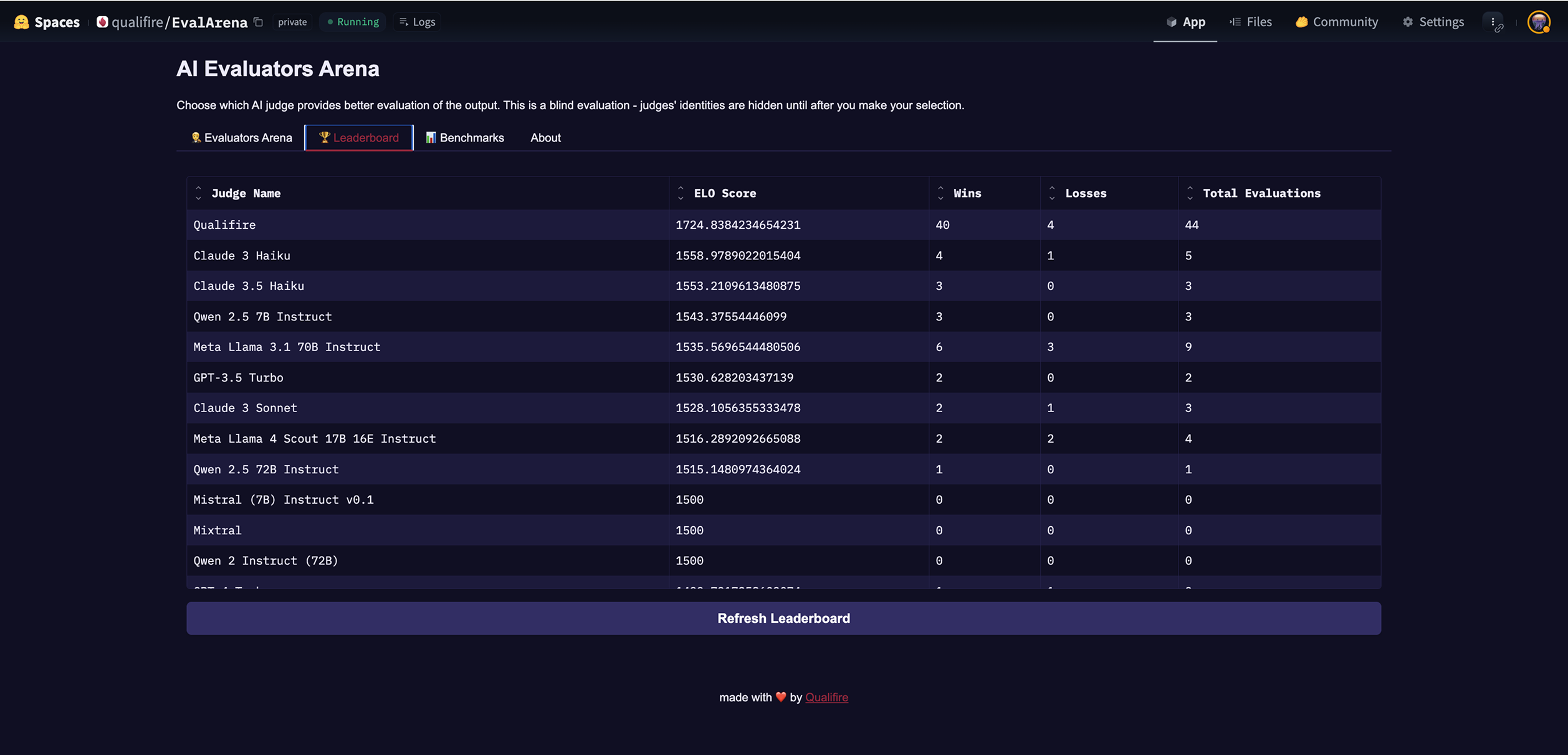
Leaderboard and ELO, explained
EvalArena uses an ELO rating to aggregate human preferences across pairs of matches. When a judge wins an evaluation, its ELO increases; when it loses, it decreases. Over time, ELO produces a ranked signal that highlights judges that align with human preferences more consistently, making it easier to select or tune a judge for production evaluation flows. This comparison, ELO-based approach echoes prior work that measures benchmark noise and model rank stability using comparisons.
How engineers can use EvalArena today
- A/B judge selection: Compare two evaluation strategies, for example a rule-based judge versus a small LLM judge; pick the one humans trust more.
- Dataset triage: Identify examples that consistently confuse judges; add them to your high-importance test set.
Qualifire’s SLMS are in the lead - test for yourself!
Want that level of evaluation in your AI stack? Sign today for free\
AI Evaluator Arena: Blind comparisons for AI judges




.png)